n-gramas permite ver qué con qué frecuencia aparecen palabras en
artículos periodísticos de Colombia.
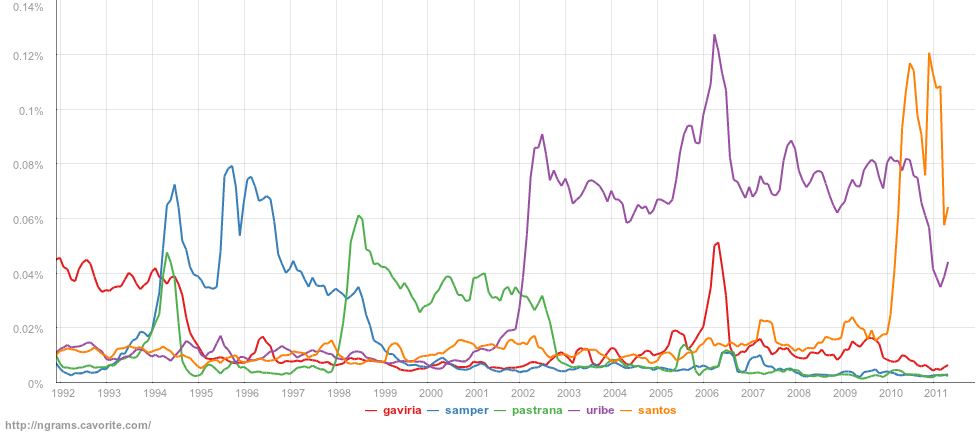
Por ejemplo, al buscar gaviria, samper, pastrana, uribe, santos, los apellidos de los últimos presidentes, se puede ver la atención de la prensa que tenían antes, durante y después sus periodos de mandato.
Búsqueda avanzada
- Utilice
*para buscar todos los términos que comienzan por una serie de letras. Por ejemplo, econom* encontrará economía, economista, económico, etc.. - Para incluir también los términos que incluyen otras palabras, utilice
**al final. Por ejemplo, elecciones** incluiría elecciones presidenciales, elecciones legislativas, etc..
Preguntas frecuentes
- ¿Qué datos se están utilizando?
-
Los datos provienen de tres publicaciones colombianas: el periódico El Tiempo y
las revistas Semana y Dinero. La muestra utilizada contiene aproximadamente 1'850.000
artículos publicados desde julio de 1982 hasta julio de 2011.
Publicación Desde Hasta Artículos El Tiempo Enero de 1990 Julio de 2011 1'652.377 Semana Julio de 1982 Julio de 2011 129.841 Dinero Enero de 1993 Marzo de 2011 67.556 - ¿Es esto una copia descarada de Google Books Ngram Viewer?
- Sí, pero al utilizar información más específica sobre Colombia permite ver las tendencias locales que no se pueden detectar en la colección de libros tan general como la que utiliza GBNV.
- ¿Hay alguna diferencia entre mayúsculas y minúsculas?
- No, por ahora se ignoran esas diferencias. El resultado es el mismo al buscar "Popayán" o "popayán". Sin embargo, la eñe sí es relevante.
- ¿Puedo buscar algo entre comillas?
- No es necesario. Cuando escribe más de una palabra se buscan esas palabras juntas, en secuencia. Así que la búsqueda entre comillas funciona por omisión. Si busca "Corte Constitucional" (con o sin las comillas), la gráfica mostrará la frecuencia de aparición de esas dos palabras juntas, es decir, ese digrama (o bigrama o 2-grama).
- ¿Por qué no hay resultados para algunas palabras que sí están en los artículos?
- El buscador incluye únicamente las secuencias de palabras que aparecen más de 10 veces en todo el año. Esto se hace para reducir el tamaño del índice removimiendo así las secuencias menos relevantes.
- ¿Puedo acceder a la base de datos?
- Podría ser posible. Puede consultar más detalles acerca de la base de datos.
- Tengo otra pregunta o encontré un problema, ¿qué puedo hacer?
- Por favor, escriba un mensaje a .
Colofón
Estos son algunos de los programas que se utilizaron para n-gramas:
- Python y Scala, para el procesamiento de los datos.
- Django, para la interfaz web.
- Dygraphs, para las gráficas incluyendo una extensión para exportarlas como archivos PNG.
n-gramas es un proyecto elaborado por
Juan Manuel Caicedo con el apoyo de la
Facultad de Economía de la Universidad de los Andes.